
















全文转载 | Chiplet双向互连,如何把BER分析做得又快又准?
-
 2026.05.18
2026.05.18
以下文章来源于公众号:信号完整性设计 ,作者:信号完整性设计
Chiplet互连正把系统设计推向一个更苛刻的边界:既要更高带宽,也要更低功耗,还要把链路误码率压到极低水平。问题在于,传统瞬态仿真虽然准确,却很难支撑超低BER目标下的大量设计迭代;而过度简化的快速统计方法,又往往抓不住Simultaneous Bi-Directional链路里最麻烦的那类噪声——自干扰。DesignCon 2025上的这篇论文,试图解决的正是这个矛盾。
做Die-to-Die互连的人都知道,真正困难的地方,从来不只是把数据“送过去”,而是要在面积、功耗、引脚数和目标BER之间找到一个可量产的平衡点。尤其在Chiplet架构下,带宽密度持续上升,封装内部互连越来越短、越来越密,系统对于每一个pin的效率都变得极其敏感。
正因如此,Single-ended Simultaneous Bi-Directional,简称SBD,成为近年来非常受关注的一类链路架构。它的直接吸引力很简单:在相同baud rate下,SBD可以把每pin带宽翻倍。论文中提到,NVIDIA在2023年展示的SBD方案可达到50.4 Gb/s/pin,而ODSA提出的BoW Turbo接口也将SBD用于高性能chiplet互连。
但带宽翻倍的代价,并不是一句“收发同线”就能概括的。SBD真正的难点,在于近端发送信号会反过来干扰本端接收信号。这类噪声在论文中被称为self-interference,自干扰。如果它建模不准,那么你看到的眼图、时序裕量甚至最终BER,都会比真实系统“好看”。

图1|SBD信号设计方案
为什么这篇论文值得看?
这篇论文真正有价值的地方,不是再讲一遍SBD的基本概念,而是回答了一个很现实的问题:当目标BER已经低到UCIe这类系统要求的量级时,怎样才能既保住仿真精度,又不把计算成本推到不可接受的程度?
文中给出了一个非常典型的背景数字:对于chip cluster系统,UCIe提出PHY raw wire BER需要低于1e-27,才有机会在没有CRC和链路重传机制的前提下,满足极低FIT目标。这个数字本身就说明,面向下一代Chiplet的高速I/O,已经不能只靠“跑一跑瞬态仿真看看眼图”来完成设计闭环。
传统瞬态仿真有一个天然问题:它很准,但对于超低BER分析来说太慢、太重。尤其当设计空间里同时存在通道、驱动器、接收端、抖动、串扰、相位偏差和训练机制等多个变量时,工程团队几乎不可能只用全瞬态方式快速完成多轮架构迭代。
而另一边,过于理想化的统计方法又容易失真。因为SBD链路并不是一个标准的LTI问题,它的关键噪声项self-interference本身就带有非线性、边沿不对称和状态相关特征。如果方法还是停留在“单bit响应 + 线性叠加”的层面,那么速度虽然有了,可信度却可能不够。

图2|SBD信号中的自干扰
SBD链路的麻烦,本质上是什么?
这篇论文以Replica Driver Bidirectional为例来展开分析。它的基本思路是:在接收端想办法生成一份本端发送信号的“副本”,再把这份副本从接收到的混合信号里减掉,从而分离出远端来的有效数据。
问题恰恰出在这里。理论上,“复制并相减”听起来很干净;但工程上,几乎没有哪条副本路径能做到与主路径完全一致。
论文把这种不一致的来源拆得很清楚,主要包括三类:
主驱动与副本驱动的增益不匹配:因为两者看到的负载阻抗不同,主驱动面对的是实际通道,而副本驱动看到的可能更多是接收端输入电容。
时序不匹配:主路径和副本路径的时钟树偏斜、驱动级尺寸差异,都会引入timing mismatch。
接收端模拟前端的非理想性:差分放大器本身存在offset和nonlinearity,接收机输入输出关系并非严格线性。
换句话说,self-interference并不是一个固定噪声源,而是一个与发射边沿、接收状态、相位关系和接收机工作点都相关的动态误差项。
这也是这篇论文很值得借鉴的地方:它没有把自干扰简单处理成“额外串扰”,而是把它当作一种需要专门分类建模的近端噪声机制来分析。

图3|主驱动与副本驱动失配引发的自干扰
为什么传统快速BER方法不够?
文中对统计眼图分析的流程做了一个很清晰的回顾。标准做法通常是:
先得到通道噪声的概率密度函数,包括ISI和串扰;
再加入发送端抖动噪声,如PSIJ、DCD、RJ;
将这些噪声卷积,得到pre-aperture BER eye;
最后再与接收端采样分布卷积,得到最终BER eye。
这个流程本身没有问题,问题在于:第一步中的“通道噪声”到底怎么建。
论文列出了三种常见响应建模方法:
SBR,Single-Bit Response:快,但默认系统近似LTI;
DER,Double-Edge Response:同时考虑上升沿和下降沿差异;
MER,Multiple-Edge Response:进一步引入历史bit pattern影响,用于更强的非线性建模。
如果是普通单向线性链路,SBR往往已经够用;但对SBD来说,问题恰恰在于它的误差高度依赖边沿方向和状态组合。因此,这篇论文选择了DER作为核心折中方案:一方面保留边沿不对称信息,另一方面避免高阶MER带来的计算爆炸。
从建模哲学上看,这其实是一种很典型的工程取舍:不追求把所有非线性都一把抓尽,而是优先把对结果影响最大、同时又能较高效建模的那一部分抓住。

图4|快速统计BER仿真流程

图5|SBD建模中的SBR、DER与MER
论文的方法,核心创新在哪里?
这篇论文提出的核心方法,可以概括成一句话:用DER建立一种适合SBD自干扰的快速统计建模方法。
它抓住了self-interference最关键的三个非理想因素:
1)发送端上升沿和下降沿不对称
在单端高速链路中,pull-up和pull-down路径往往并不完全对称。论文指出,这种不对称在大多数DDR和D2D缓冲器中都很常见,因为PMOS和NMOS的器件特性不同,即使做了on-resistance校准,也很难覆盖所有PVT变化。
这会直接带来两个后果:
接收眼图出现垂直不对称;crossing level偏离中点,进一步侵蚀电压和时间裕量。
也正因为如此,自干扰不能只建一个统一响应,而要区分rising edge和falling edge的影响。

图6|发送端上升沿与下降沿对应的自干扰边沿响应
2)接收端 vout-vin 特性非线性
第二个关键点来自接收端。论文明确指出,高速接收机前端的差分放大器、CTLE、DFE等模块都包含一定程度的非线性。尤其在Replica Driver SBD结构里,接收端的输入输出关系并不是一个固定线性函数。
更重要的是,接收端的工作点会随着入射信号共模变化而变化。也就是说,接收机对self-interference的“滤波方式”本身也会变。
这意味着,自干扰不只与发送端状态有关,还与inbound received signal当前是高还是低有关。论文中的仿真结果表明,当接收信号为高电平时,自干扰幅度会更大。

图7|接收端的非线性 vout-vin 特性

图8|不同接收数据状态下的边沿响应
3)双Die之间的相位关系不确定
第三个关键因素,是SBD链路在系统级实现中绕不过去的问题:两个Die之间的相位差。
论文给出的系统结构是典型的delay-matched clock-forwarding architecture。每个die都有本地PLL和时钟通道,接收端需要获得精确的90°相移,才能在眼图中心采样数据。现实里,这个相位关系并不是天然固定的,通常还要靠LCDL等训练机制去校准。
这就带来一个非常实际的问题:如果两个die之间存在phase skew,那么近端发射引入的self-interference就可能落到接收眼图的不同位置。有些时候它压在眼图边缘,有些时候则直接切进关键判决窗口。
论文用Figure 12和表格给出了很直接的结果:当两端相位差从0到50ps变化时,眼高和眼宽会出现明显波动。在某些相位点,自干扰会严重压缩系统timing window。
这也是为什么作者进一步区分了两种建模场景:
没有phase training机制:自干扰出现时间可视为在1UI内均匀分布,需要对不同phase difference下的pdf做平均;
有phase training机制:只需要在某个确定phase difference下建模即可,复杂度大幅下降。

图9|不同相位差下的BER眼图

图10|无相位训练时的统计结果

图11|有相位训练时的统计结果

图12|不同相位差下的统计BER眼图
这篇论文最硬的结果是什么?
如果只用一句话概括论文结果,那就是:它用DER方法,在保持较高精度的同时,把SBD自干扰纳入了快速统计BER分析流程。
论文给出的验证场景是一个16Gbps SBD interposer channel:
通道长度约 2 mm
选用 4层铜互连结构
在Nyquist频率下插损约 2.28 dB
随后,作者将提出的DER统计方法与SPICE瞬态仿真做对比,使用的是1e6 bit PRBS数据模式,并考察了不同相位差场景。
结果非常关键:
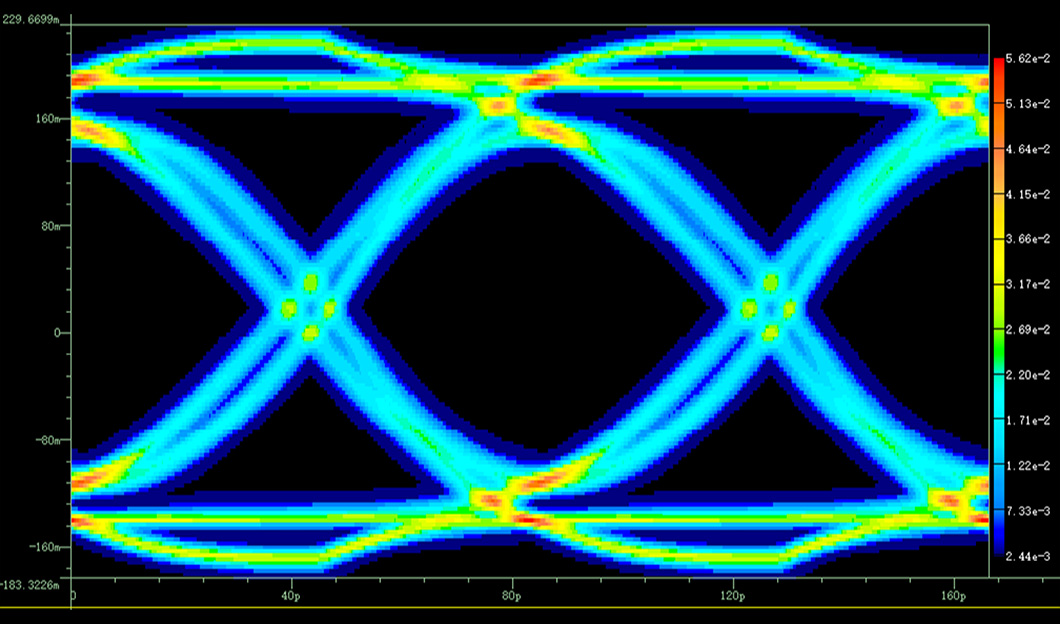
在0ps相位差时,瞬态仿真的眼高为 468 mV,DER方法为 453 mV,误差约 3.2%
眼宽分别为 116 ps 和 120 ps,误差约 3.4%
在30ps相位差时,眼高误差约 1.3%,眼宽误差约 2.8%
论文总结的总体结论是:眼高和眼宽误差都可以控制在5%以内。
这组结果的重要性在于,它证明了DER并不是一个“只看趋势”的粗略模型,而是已经足够接近SPICE,能够支撑前期架构评估和大规模参数扫描。

图13|16Gbps SBD interposer 通道

图14|DER与SPICE的BER结果对比
论文还给了哪些工程启示?
这篇论文并不只是停留在“提出一种仿真方法”,它还进一步问了一个工程上更重要的问题:如果知道self-interference会伤害系统,我们该如何管理它?
作者最后专门分析了两个设计变量:
TX timing mismatch
RX amplification factor
结果很有代表性:
timing mismatch增加时,眼宽会下降;
amplification factor增加时,虽然眼高会上升,但眼宽反而会下降。
这意味着,设计并不是“把接收增益尽量做大”就完事了。相反,系统需要在电压裕量和时间裕量之间重新平衡。论文给出的建议是:
接收放大能力应当选在一个居中的范围
timing mismatch最好控制在3ps以内
这类结论对工程团队尤其有价值,因为它把一个原本偏抽象的建模论文,转化成了可落地的设计边界。

图15|TX时序失配与RX放大因子对BER眼图的影响
对SIPI和产业链意味着什么?
从SIPI视角看,这篇论文反映的不只是一个局部算法优化,而是一个很清晰的趋势:Chiplet时代的高速互连分析,正在从“单纯追求精度”走向“精度与效率并重”的新阶段。
这背后至少有三层意义。
第一,统计仿真方法必须开始更认真地处理非线性与状态相关噪声。
过去很多快速方法默认链路近似LTI,但SBD这类架构提醒我们,未来越来越多高带宽互连未必满足这种理想假设。
第二,训练机制本身也要进入系统级建模。
论文关于phase training的讨论很重要,因为它说明系统表现并不只取决于channel和buffer,还取决于训练机制能否把工作点拉回更优区域。
第三,方法论上的“够准且够快”会越来越有产业价值。
当设计空间、PVT组合、封装拓扑和lane数量都迅速增加时,谁能用更高效的方法更早发现margin风险,谁就更有可能在量产前把架构问题解决掉。
对EDA工具、Chiplet PHY IP、先进封装协同设计来说,这样的方法都很有现实意义。它不一定是最终的全能解,但很可能是一条非常务实的中间路线:先用DER把最关键的非理想抓住,再把更强的非线性问题交给后续MER或更高保真模型处理。
写在最后
这篇DesignCon 2025论文最值得记住的,不只是“提出了一种DER方法”,而是它把SBD链路分析里最难被忽略的现实说透了:真正决定你能不能把BER分析做快、做准的,不只是算法本身,而是你有没有把self-interference这类状态相关噪声认真纳入模型。
对今天的Chiplet互连来说,带宽翻倍的诱惑很大,但如果没有一套足够高效且足够可信的分析方法,这种架构优势就很难真正变成量产价值。
这也是这篇论文给行业的启发:当高速I/O进入Chiplet深水区,仿真方法本身已经不只是“验证工具”,而是在定义架构迭代速度和设计边界。
一句话总结:下一代Chiplet双向互连的挑战,不只是更高BER目标,而是如何用足够快的方法,准确抓住自干扰这种最关键的系统噪声。
你认为,在Chiplet D2D链路持续升速之后,DER这类折中建模方法会不会成为下一阶段SI工具链里的标配?欢迎留言交流。
参考论文
论文来源:Tingting Pang(T-Head Semiconductor Co., Ltd.), Yanbin Chen(T-Head Semiconductor Co., Ltd.), Jialong Dong(Julin Technology Co., Ltd.),DesignCon 2025
论文题目:Fast BER Analysis Technique for Next Generation Chiplet Simultaneous Bi-Directional Transceiver








