
















高速接口的速率翻了十倍,SI/PI仿真的难度何止翻了十倍
-
 2026.04.14
2026.04.14
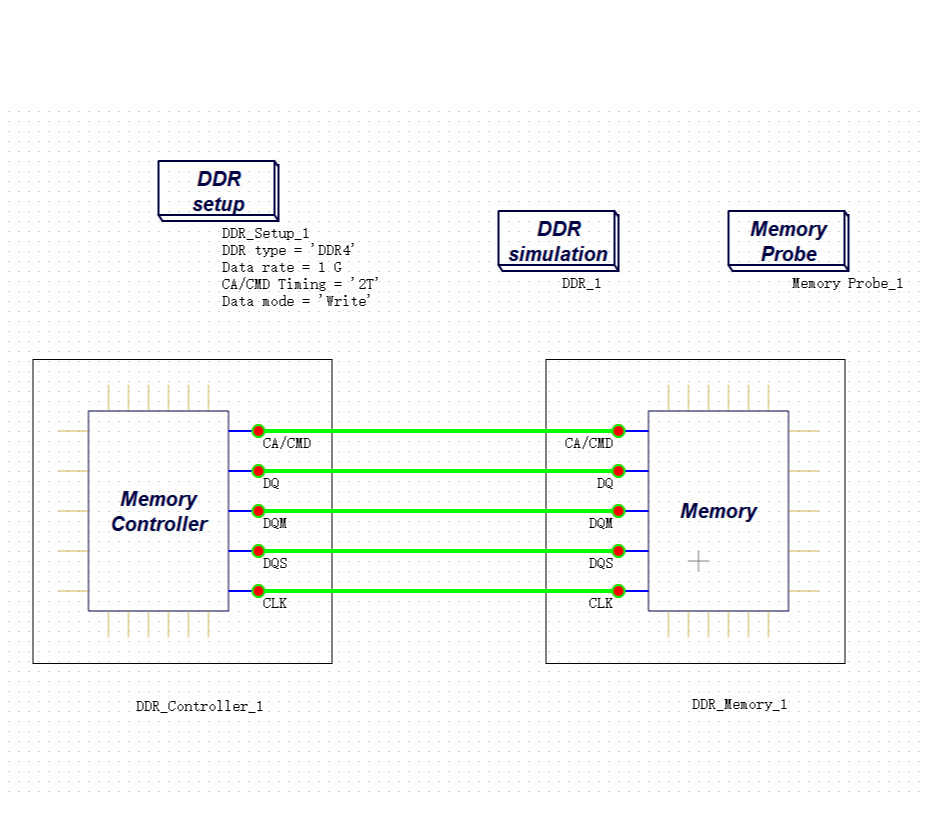
2003年,DDR1的数据速率是400 Mbps。
2025年前后,DDR5 最新规格已突破 8000 Mbps,HBM3E(9.6 Gbps/pin)实现大规模量产,PCIe Gen6(64 GT/s)也进入量产落地阶段。

二十年,速率翻了20倍。
做信号完整性的工程师知道这意味着什么——不只是信号跑得更快了,而是原来那套仿真方法,正在一个接一个地失效。
一、第一个失效:宏模型跟不上了
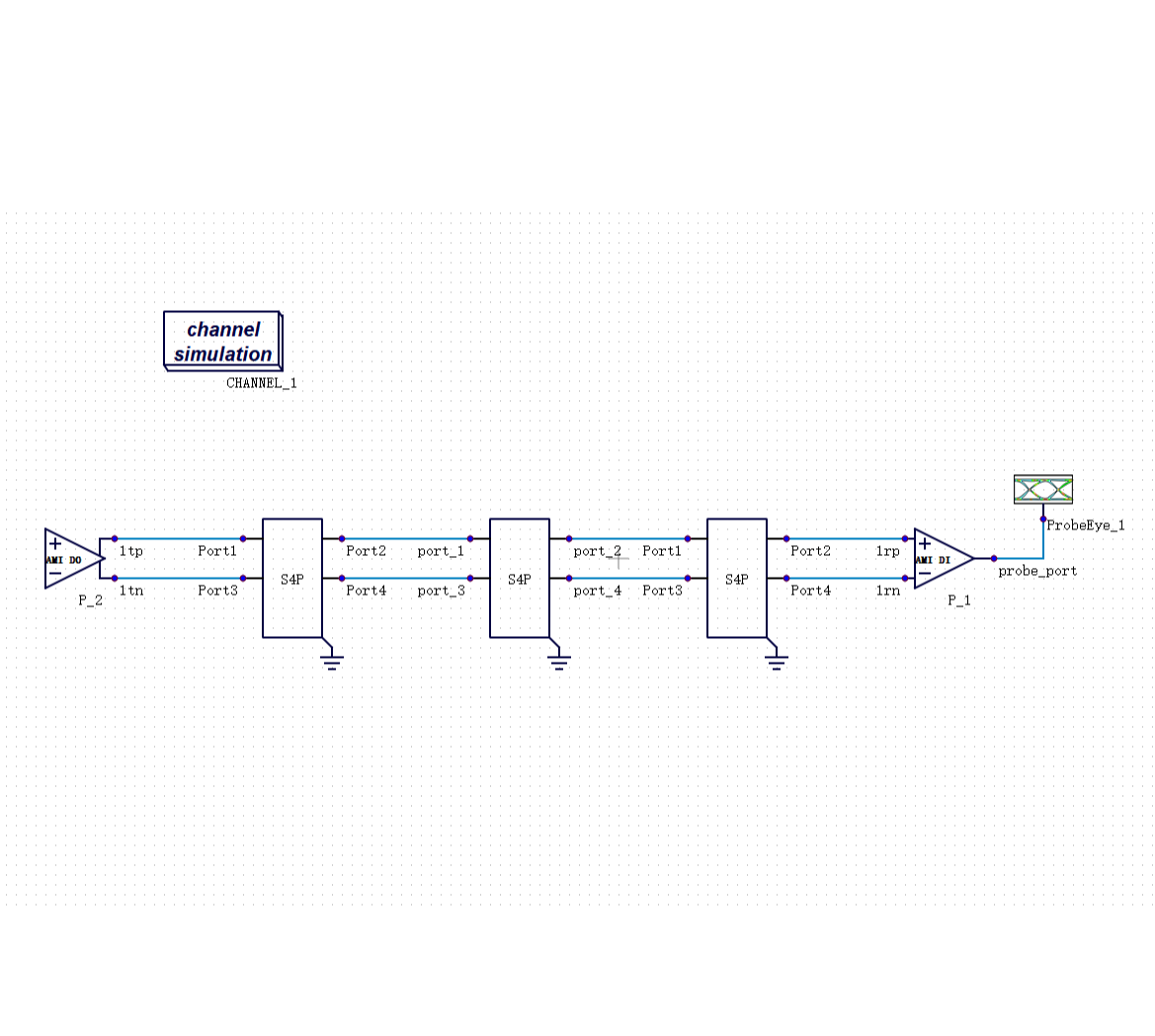
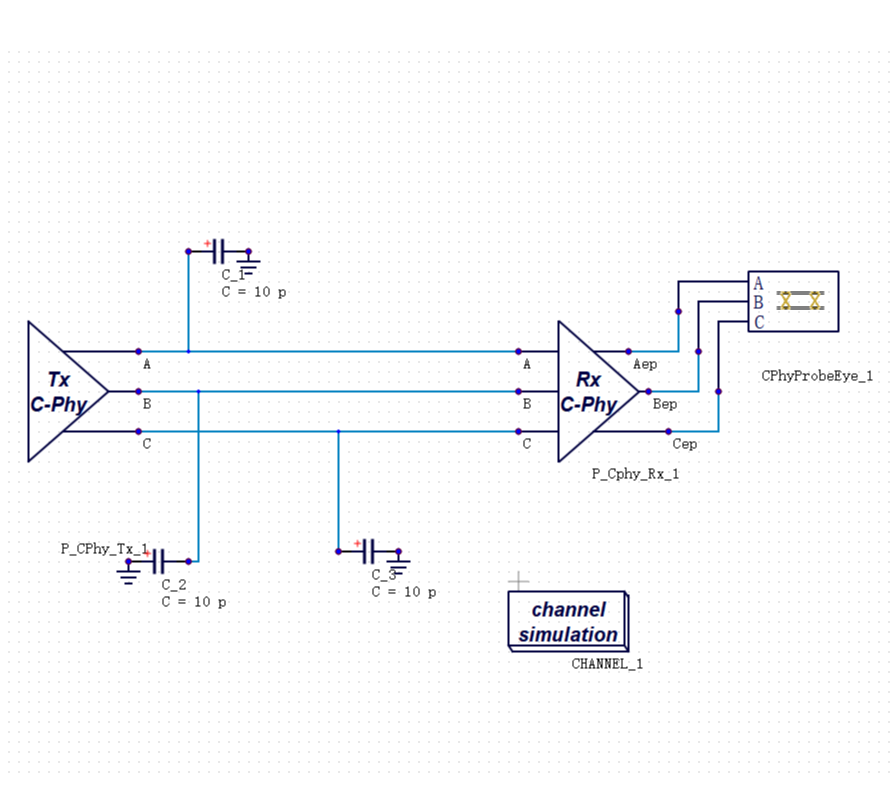
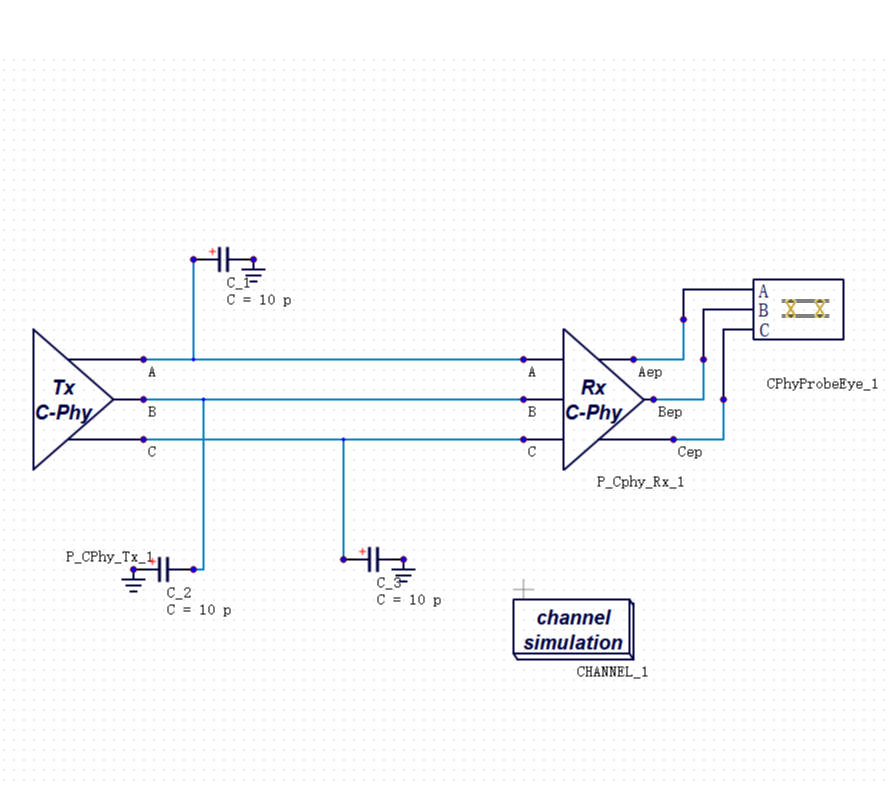
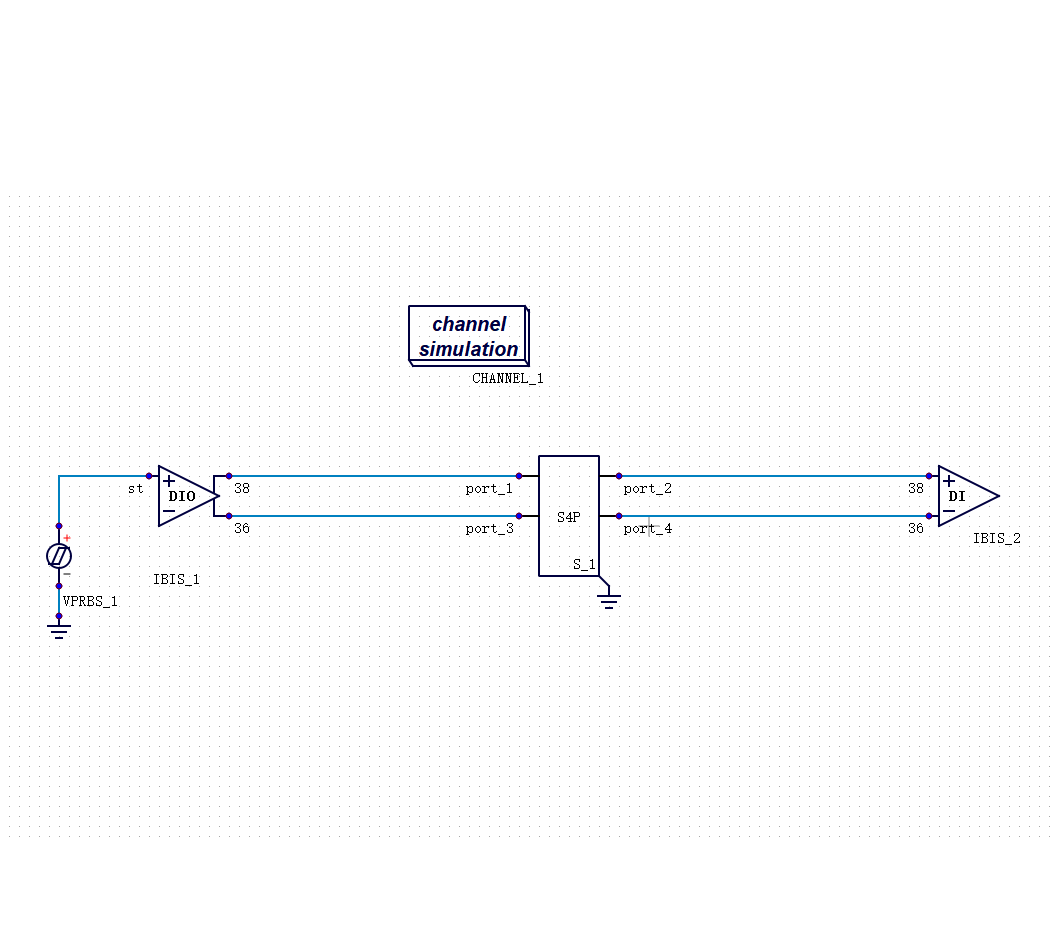
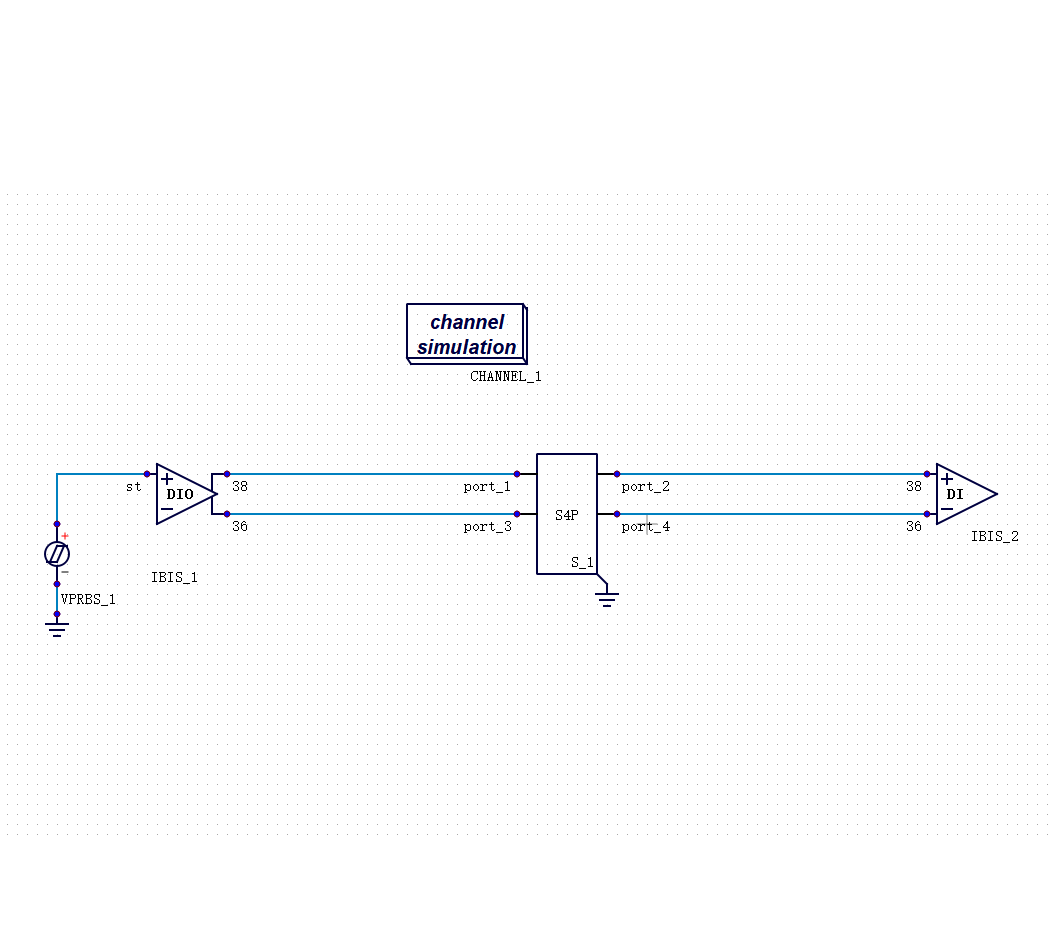
做高速接口仿真,IBIS 模型是绕不开的工具。
它的逻辑很直接:用一个行为级宏模型来描述芯片的 I/O 特性,不需要知道芯片内部的电路细节,也能做通道仿真。这个方法在 DDR3、DDR4 时代非常够用。
但到了 DDR5、HBM3、PCIe Gen5 这个速率区间,问题来了。
宏模型是对芯片行为的近似描述。 速率越高,芯片 I/O 的非线性特性越复杂,近似误差就越大。在极端工况下——高温、低压、最差 PVT Corner——这个误差可能已经超过了设计裕量本身的范围。
DDR5 带来了一个更根本的问题:它强制引入了均衡技术(Equalization)。传统 IBIS 宏模型完全看不见均衡之后的眼图——它描述的是芯片 I/O 的静态驱动行为,而均衡是一个动态的、依赖码型的算法过程。为此,业界引入了 IBIS-AMI 扩展模型来处理均衡建模,但 AMI 本质上仍是行为级近似,在复杂场景下依然存在精度天花板。AMI 并非没有价值——在结合时域仿真的混合方案中,它可以提供均衡建模的功能支撑;局限在于,不能把 AMI 单独作为高速接口 Signoff 的精度基准。
工程师仿真出来说裕量够,流片回来实测说裕量不够。根本原因往往就在这里。
二、第二个失效:分开仿真的误差在累积
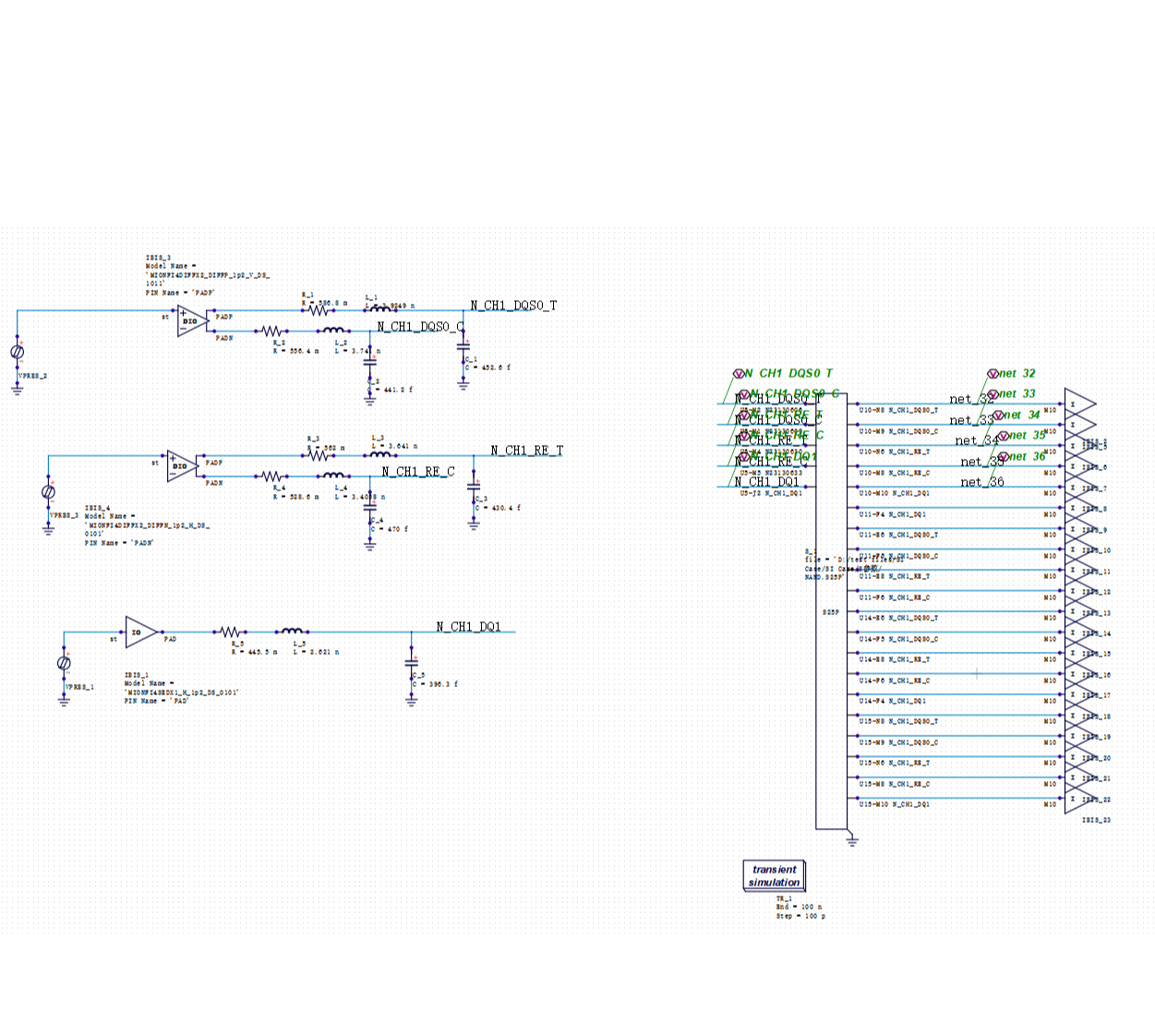
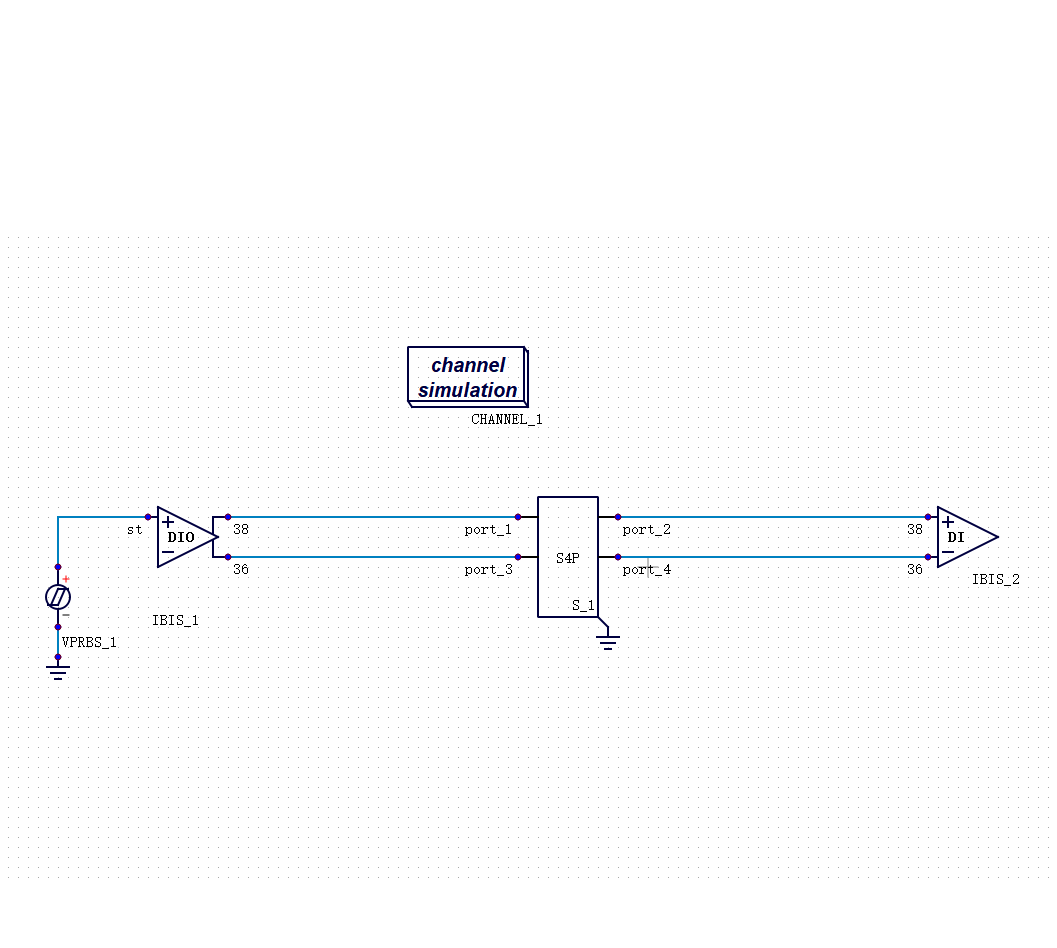
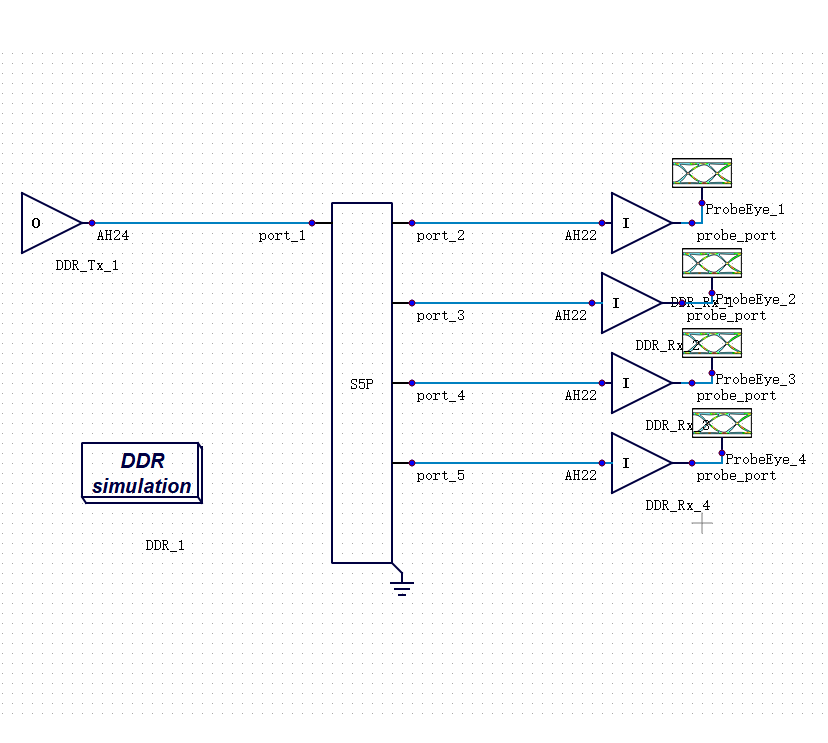
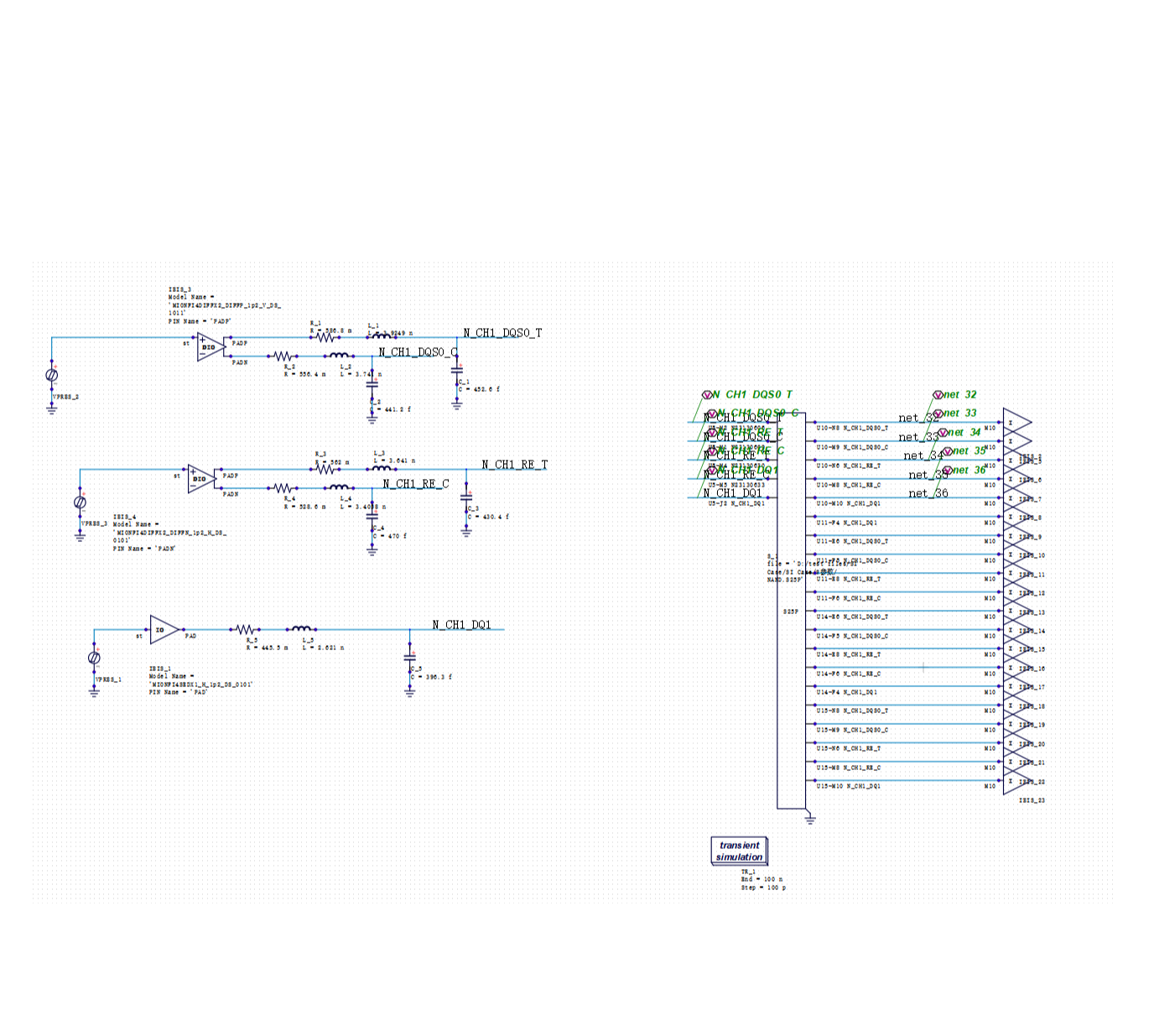
传统的 SI/PI 仿真流程,是把芯片、封装、PCB 分层处理的:先提取芯片的 I/O 模型,再单独建封装的寄生参数模型,再做板级的传输线仿真,最后把结果叠在一起看。
这个方法在低速时代没有问题,因为各层之间的相互影响很小,分开算再叠加,误差可以接受。
到了高速场景,这个假设开始崩塌。
封装的寄生电感,会和芯片 I/O 的驱动能力相互作用;PCB 上的阻抗不连续,会在封装引脚处产生反射,再影响芯片端的波形。这些是系统级的耦合效应,分层建模本身就丢掉了这部分信息。
每一层单独仿真"都过了",合在一起却不满足时序要求——这种情况,在 DDR5 和 HBM 项目里已经越来越常见。
三、第三个失效:仿真方法论本身有分歧
工程师面对的困境,有时候不是"工具不够好",而是"不知道该用哪种方法"。
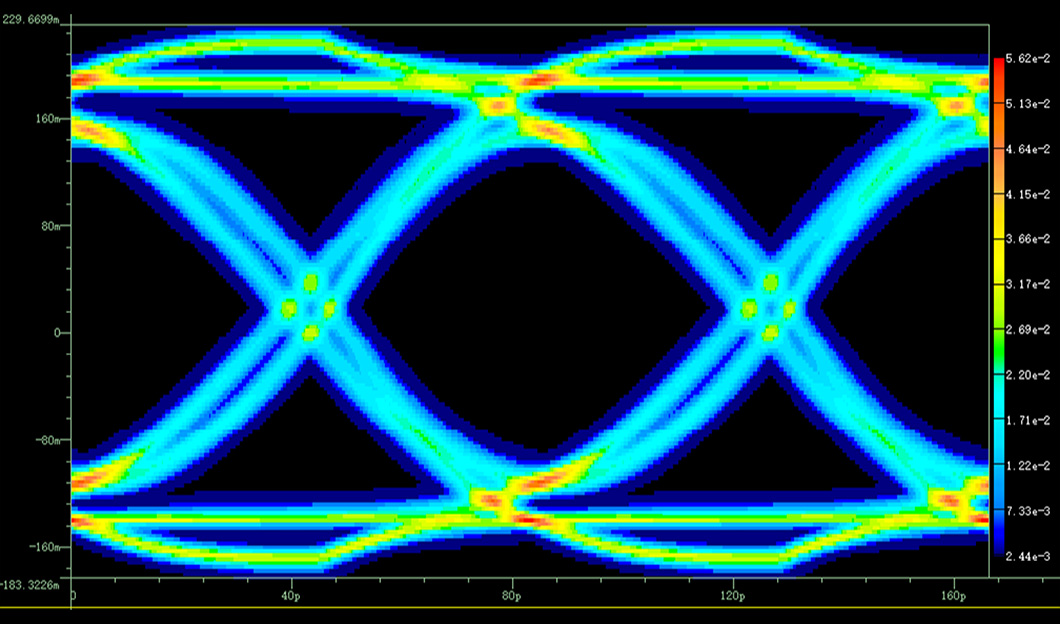
以 BER(误码率)Signoff 为例,目前业内主要有两种路线:
·统计分析法(Channel Simulation):最早为 SerDes 接口设计,后来延伸用到 DDR 接口。速度快,但依赖卷积/累加算法,在非线性较强的场景下精度会下降。
·瞬态仿真法(Transient):精度更接近真实物理行为,但计算量大,跑完一个完整场景耗时极长。工程师不知道该信哪个,或者两个都跑,但没有足够的时间。
两种方法各有取舍,但 DDR5 让这个矛盾变得更加尖锐——原因在于 DFE(判决反馈均衡)的引入。
DFE 是 DDR5 相比 DDR4 最关键的架构差异之一。它的工作方式是根据已判决的历史码元,实时消除码间串扰(ISI)。这个"依赖历史决策"的反馈机制,打破了统计分析法的一个核心假设:信号是平稳且各态历经的。统计法用卷积/累加来估算眼图,对 DFE 这类非线性均衡的处理天然存在精度损失;而瞬态法逐比特仿真,能真实还原 DFE 的实际运作过程,但计算代价极高。
两者给出的结论在 DDR5 场景下可能存在明显差异——
这不是工程师的问题,是整个行业在 DDR5 及以上接口的 Signoff 方法论上还没有形成共识的问题。
四、第四个失效:工具碎片化拖慢了整个流程
做完整的 SI/PI 分析,一个工程师往往需要同时打开多个工具:
用 A 工具跑通道仿真,用 B 工具做瞬态分析,再切到 C 工具查看波形、测量眼图参数。每个工具做好自己的那一块,但数据格式、仿真设置、波形显示各自为政。
这带来两个实际问题:
·一是效率损耗:在工具之间反复导入导出数据,排查问题时要在多个界面之间切换,本来几小时能完成的分析,可能花掉一整天。
·二是误差引入:数据在不同工具之间传递,格式转换和参数设置不一致,本身就会带来额外的偏差——有时候工程师以为是设计问题,其实是工具衔接的问题。

五、代价是可以量化的
上面这些失效,最终都会反映在良率上。
有数据显示,在高速接口设计中,不做仿真驱动的系统级优化(DOE/RSM),和经过完整仿真优化后的设计相比,缺陷率可以相差近一倍。
这还不算因为仿真结论不可靠导致的重新流片成本,以及项目周期延误的代价。
六、一个正在扩大的缺口
DDR5、HBM3、UCIe、PCIe Gen5——这一代高速接口标准,已经把 SI/PI 仿真推到了原有方法论的边界。
速率还在涨。Chiplet 封装把芯片间互连的复杂度又推上了一个台阶。工程师面对的,是四个同时存在的困境:模型精度不够、分层仿真误差累积、方法论没有共识、工具流程碎片化。
这不是某一个问题,而是整个仿真体系在高速时代的系统性压力。








